Veja como facilmente criar gráficos dos dados disponíveis nesse pacote.
library(amazonasdatahub)
Tutoriais das bases de dados
Para cada base de dados, você pode verificar a documentação
correspondente usando um ? (ponto de interrogação) antes do nome da
base de dados.
?agriculture_idam
?aids_amazonas
?humidity_manaus
?malaria_amazonas
?pib_trimestral
?rionegro_amazonas
?school_read_levels
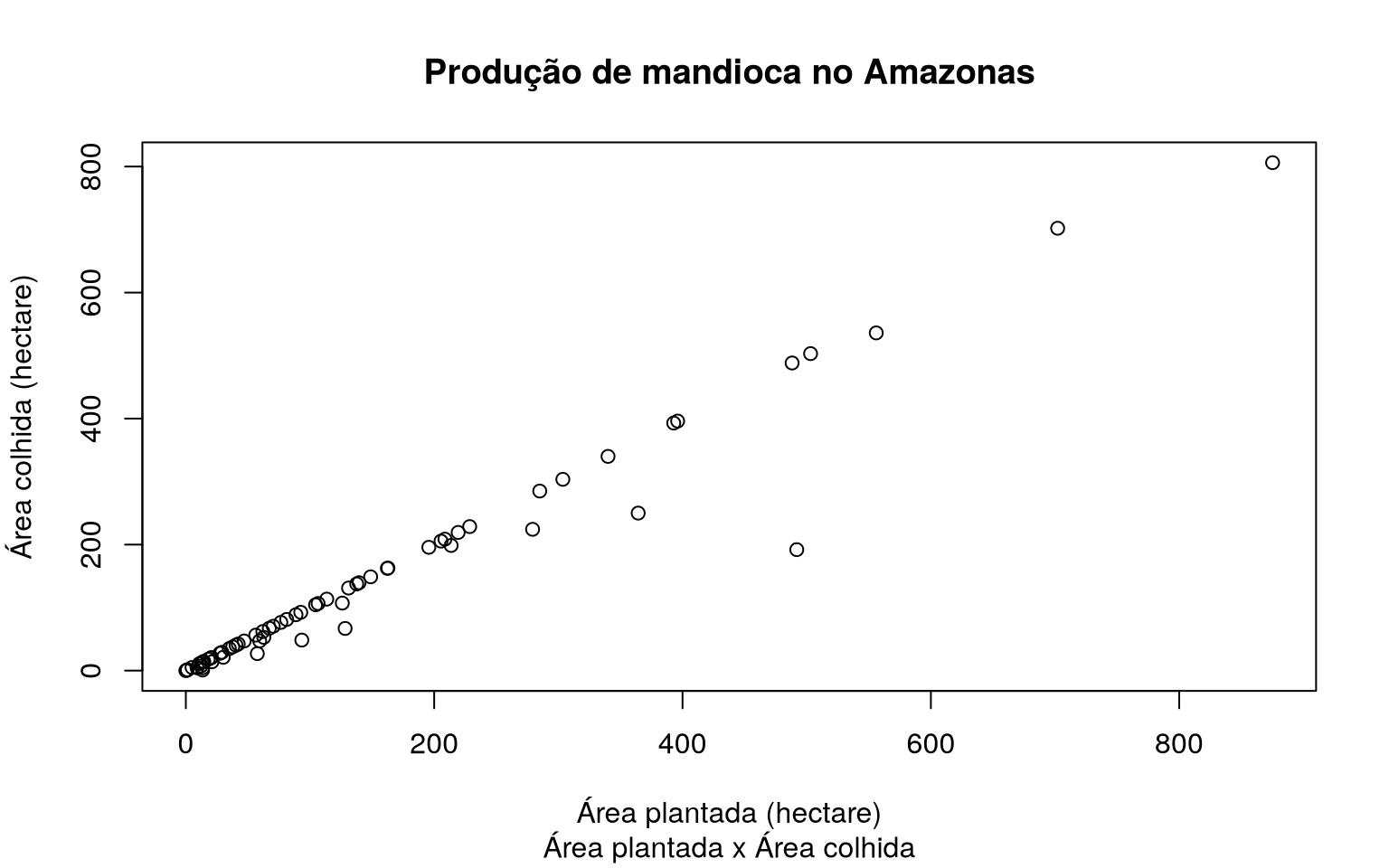
Gráfico de Dispersão entre Área plantada e Área colhida de produção de Mandioca
A base de dados agriculture_idam fornece dados de produção agrícola do
Amazonas. Podemos visualizar a dispersão da área plantada e da área
colhida de diferentes produções, mas para esse exemplo, usaremos dados
de produção de mandioca.
Para plotar um gráfico de dispersão simples no R, sem utilizar outros
pacotes, utilizaremos a função plot.
# Filtrando dados
mandioca_prod <- agriculture_idam[agriculture_idam$cultivation == "Mandioca", ]
# Plotando o grafico
plot(
mandioca_prod$planted,
mandioca_prod$harvested,
xlab = "Área plantada (hectare)",
ylab = "Área colhida (hectare)",
main = "Produção de mandioca no Amazonas",
sub = "Área plantada x Área colhida"
)
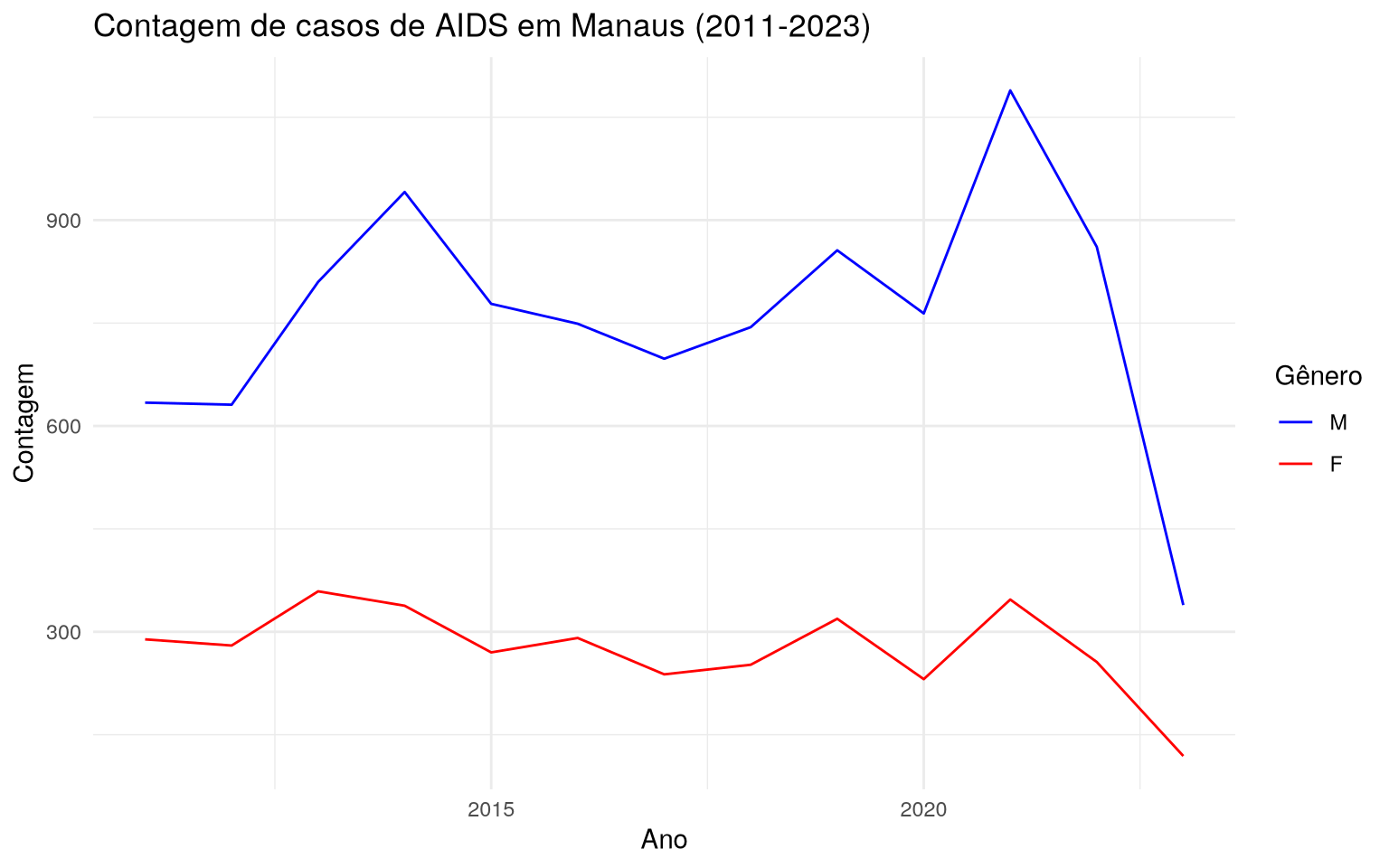
Série temporal da contagem de casos de AIDS em Manaus
A base de dados aids_amazonas fornece dados das ocorrências de AIDS
nos municípios do Amazonas.
Uma das análises que podem ser feitas é: verificar a série temporal da
contagem de casos filtrado de determinado município, onde os casos são
agrupados pelo sexo do indivíduo observado. Para fazer isso,
utilizaremos os pacotes dplyr para estruturar os dados, e o ggplot
para fazer o gráfico e customizá-lo.
# install.packages(c("dplyr", "ggplot2"))
require(dplyr)
require(ggplot2)
# Filtrando dados, agrupando e plotando:
aids_amazonas %>%
filter(name_muni == "Manaus") %>%
group_by(gender) %>%
ggplot(aes(x = year, y = cases, group = gender, color = gender)) +
geom_line() +
scale_color_manual(values = c("blue", "red")) +
theme_minimal() +
labs(
title = "Contagem de casos de AIDS em Manaus (2011-2023)",
x = "Ano",
y = "Contagem",
color = "Gênero"
)
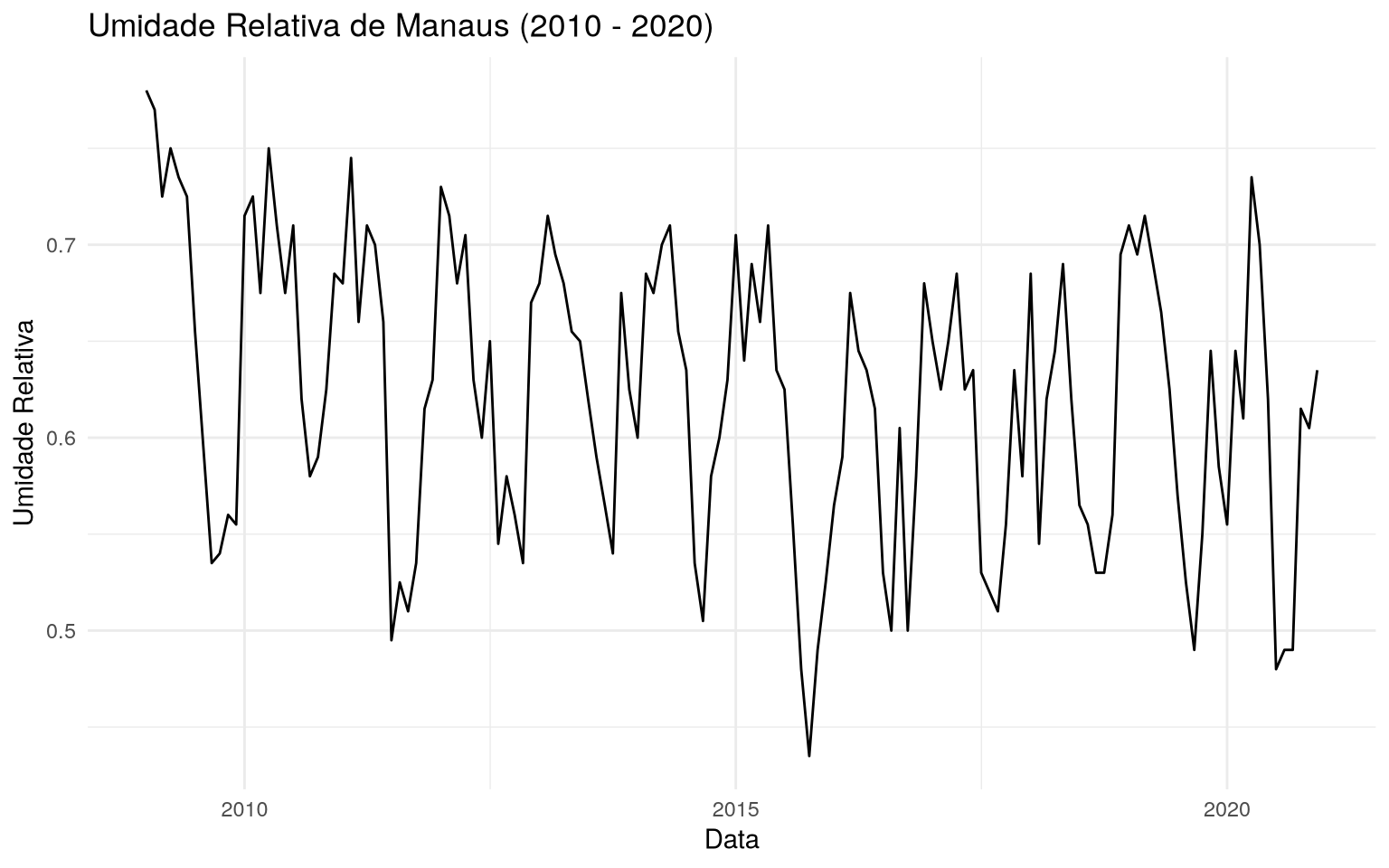
Série temporal da umidade relativa de Manaus (2010 - 2020)
Com o conjunto de dados humidity_manaus, que reune dados de umidade
relativa observados na cidade de Manaus de janeiro de 2009 a dezembro de
2020, podemos verificar séries temporais, e dentre elas, a da umidade
relativa durante esse intervalo de tempo.
Usando dplyr, podemos criar uma coluna de data, que será composta
pelos dados de mês e ano, e com o ggplot2, podemos criar o gráfico.
# install.packages(c("dplyr", "ggplot2"))
require(dplyr)
require(ggplot2)
# Criando variavel de data unindo ano e mes, e em seguida,
# plotando o grafico
humidity_manaus %>%
mutate(date = as.Date(paste0(year, "-", month, "-","01"))) %>%
ggplot(aes(x = date, y = rh)) +
geom_line() +
theme_minimal() +
labs(
title = "Umidade Relativa de Manaus (2010 - 2020)",
x = "Data",
y = "Umidade Relativa"
)
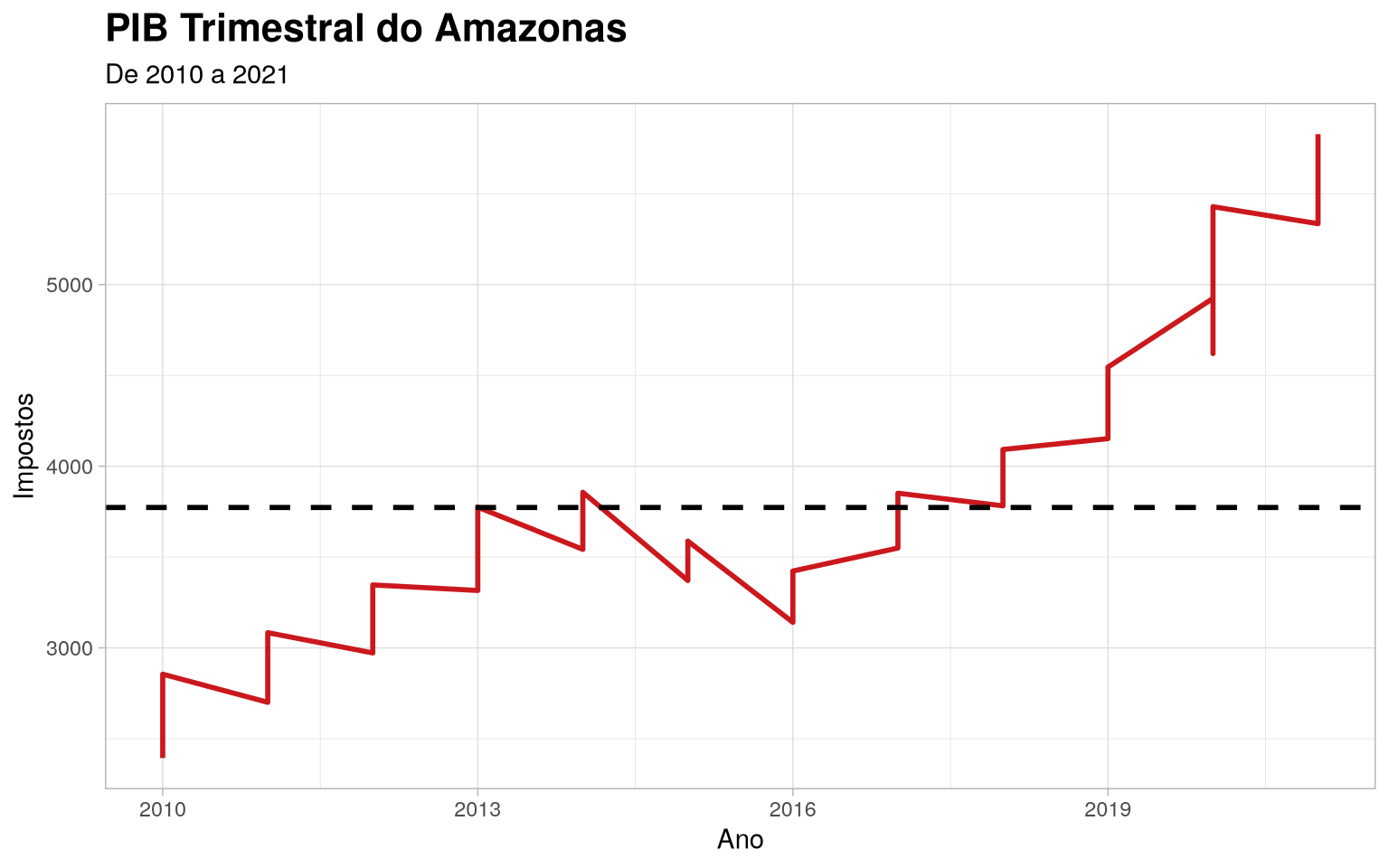
Série temporal do PIB trimestral do Amazonas
Com os dados de pib_trimestral, podemos realizar análises a respeito
dos padrões observados na distribuição de dados pelo intervalo observado
(2010 a 2021).
Utilizando dplyr, podemos selecionar as variáveis de interesse, e com
o ggplot2, criaremos um gráfico de linha. Esse exemplo mostrará essa
aplicação, além de customizações mais avançadas, incluindo cores,
formatação de fonte do título e tipos de linha.
require(dplyr)
require(ggplot2)
pib_trimestral %>%
select(year, taxes) %>%
ggplot(., aes(x = year, y = taxes)) +
geom_line(linewidth = 1L, colour = "#cb181d") +
geom_hline(
yintercept = mean(pib_trimestral$taxes),
linetype = "dashed",
size = 1
) +
theme_light() +
theme(
plot.title = element_text(face = "bold", size = 16)
) +
labs(
x = "Ano",
y = "Impostos",
title = "PIB Trimestral do Amazonas",
subtitle = "De 2010 a 2021"
)
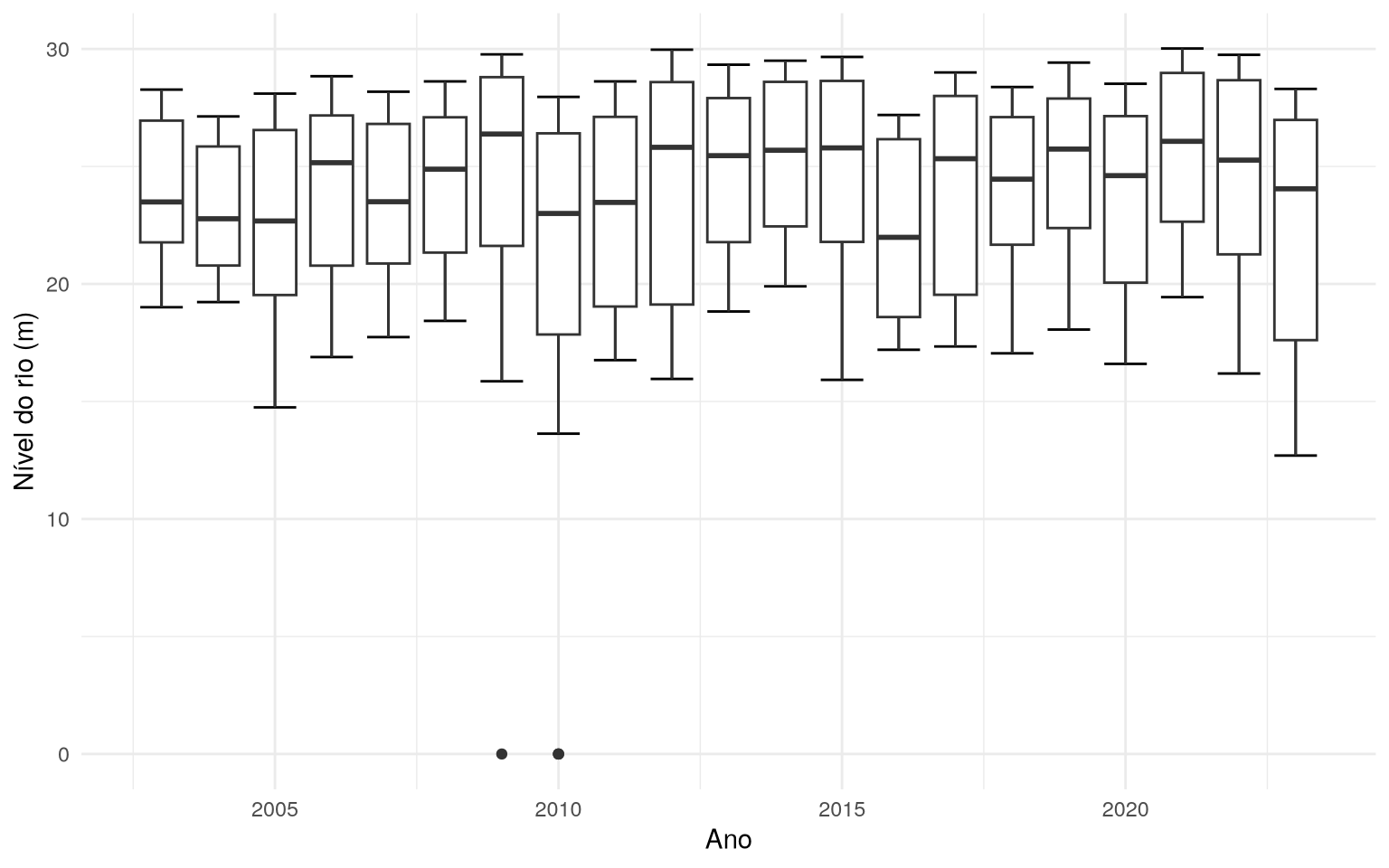
Boxplots do nível de água (em metros) do Rio Negro (Amazonas)
Com os dados do nível de água e ano do rionegro_amazonas, uma das
análises que podem ser feitas é a dos boxplots no decorrer dos anos.
Utilizaremos o ggplot2 para fazer esse gráfico.
require(ggplot2)
rionegro_amazonas %>%
ggplot(aes(x = year, y = level_m, group = year)) +
stat_boxplot(geom = "errorbar") +
geom_boxplot() +
theme_minimal() +
labs(
x = "Ano",
y = "Nível do rio (m)"
)
Code
require(dplyr)
require(ggplot2)
# Filtrando datas para o segundo semestre de 2010
rionegro_amazonas_2010_02 <- rionegro_amazonas %>%
filter(date >= "2010-06-01" & date <= "2010-12-31")
# Visualização Gráfica
rionegro_amazonas_2010_02 %>%
ggplot(., aes(x = date, y = level_m)) +
geom_line(size = 1L, colour = "#006994") +
geom_hline(
aes(
yintercept = mean(rionegro_amazonas_2010_02$level_m),
color = "Média"
),
linetype = "dashed",
size = 1
) +
geom_hline(
aes(
yintercept = min(rionegro_amazonas_2010_02$level_m),
color = "Mínimo"
),
linetype = "dotted",
size = 1
) +
geom_hline(
aes(
yintercept = max(rionegro_amazonas_2010_02$level_m),
color = "Máximo"
),
linetype = "dotted",
size = 1
) +
scale_color_manual(
name = "Estatísticas",
values = c(
"Média" = "orange",
"Mínimo" = "red",
"Máximo" = "green"
)) +
scale_x_date(
date_breaks = "1 month"
) +
theme_light() +
theme(
plot.title = element_text(face = "bold", size = 16)
) +
labs(
x = "Ano",
y = "Nível do rio em metros",
title = "Nível do Rio Negro do 2º semestre de 2010"
)
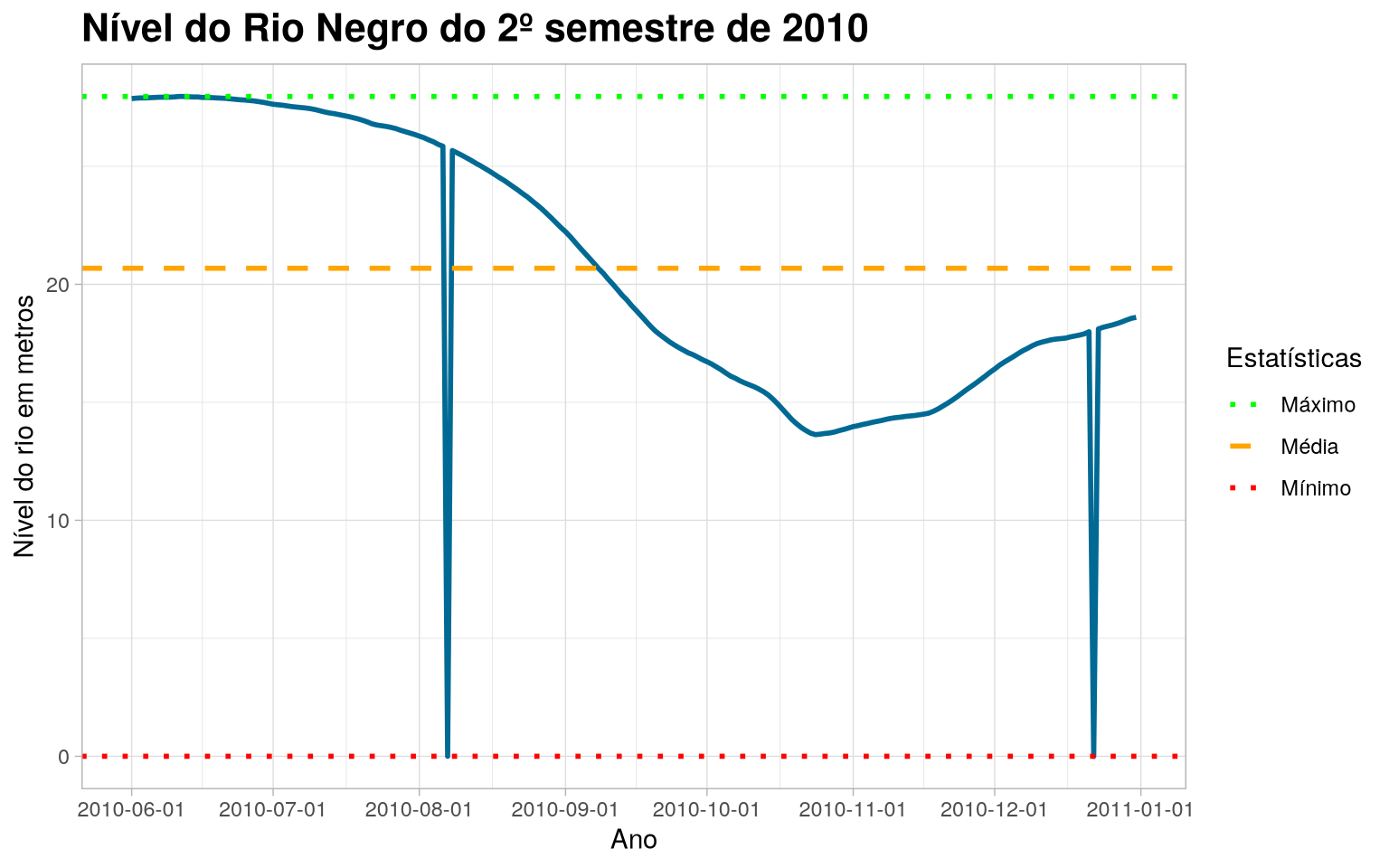
Dados faltantes e outliers
Parte do trabalho do Estatístico é identificar e encontrar certos erros e incoerências nos dados. Vejamos que o gráfico acima mostra que o nível do Rio Negro em metros esteve em 0. Isso é estranho e incomum, pois indicaria que o rio secou totalmente.
Podemos concluir que esses valores “0”, vistos no gráfico dos Boxplots, correspondem a dados ausentes (NA), os quais foram preenchidos com o valor zero. Iremos substituir esses valores zero por NAs.
require(tidyr)
rionegro_amazonas_2010_02 <- rionegro_amazonas_2010_02 %>%
mutate(
level_m = case_when(
date == "2010-08-07" ~ NA_real_,
date == "2010-12-22" ~ NA_real_,
TRUE ~ as.numeric(level_m)
),
increase_decrease_cm = case_when(
date == "2010-08-07" ~ NA_real_,
date == "2010-12-22" ~ NA_real_,
TRUE ~ as.numeric(increase_decrease_cm)
)
)
Tratamento de Valores Faltantes (NA)
Agora que definimos os valores faltantes, podemos escolher um método para tratá-los. Nesse exemplo, usaremos o Foward-Fill, mas encorajamos você a pesquisar e tentar utilizar outros métodos para aprender diferentes formas de tratamentos de valores faltantes.
require(tidyr)
rionegro_amazonas_2010_02 <- rionegro_amazonas_2010_02 %>%
fill(level_m, increase_decrease_cm)
Com os dados tratados, podemos refazer o gráfico e visualizar o nível do Rio Negro.
Visualização Gráfica do nível Rio Negro (2010/2)
Code
require(dplyr)
require(ggplot2)
# Visualização Gráfica
rionegro_amazonas_2010_02 %>%
ggplot(., aes(x = date, y = level_m)) +
geom_line(size = 1L, colour = "#006994") +
geom_hline(
aes(
yintercept = mean(rionegro_amazonas_2010_02$level_m),
color = "Média"
),
linetype = "dashed",
size = 1
) +
geom_hline(
aes(
yintercept = min(rionegro_amazonas_2010_02$level_m),
color = "Mínimo"
),
linetype = "dotted",
size = 1
) +
geom_hline(
aes(
yintercept = max(rionegro_amazonas_2010_02$level_m),
color = "Máximo"
),
linetype = "dotted",
size = 1
) +
scale_color_manual(
name = "Estatísticas",
values = c(
"Média" = "orange",
"Mínimo" = "red",
"Máximo" = "green"
)) +
scale_x_date(
date_breaks = "1 month"
) +
theme_light() +
theme(
plot.title = element_text(face = "bold", size = 16)
) +
labs(
x = "Ano",
y = "Nível do rio em metros",
title = "Nível do Rio Negro (ajustado) do 2º semestre de 2010"
)
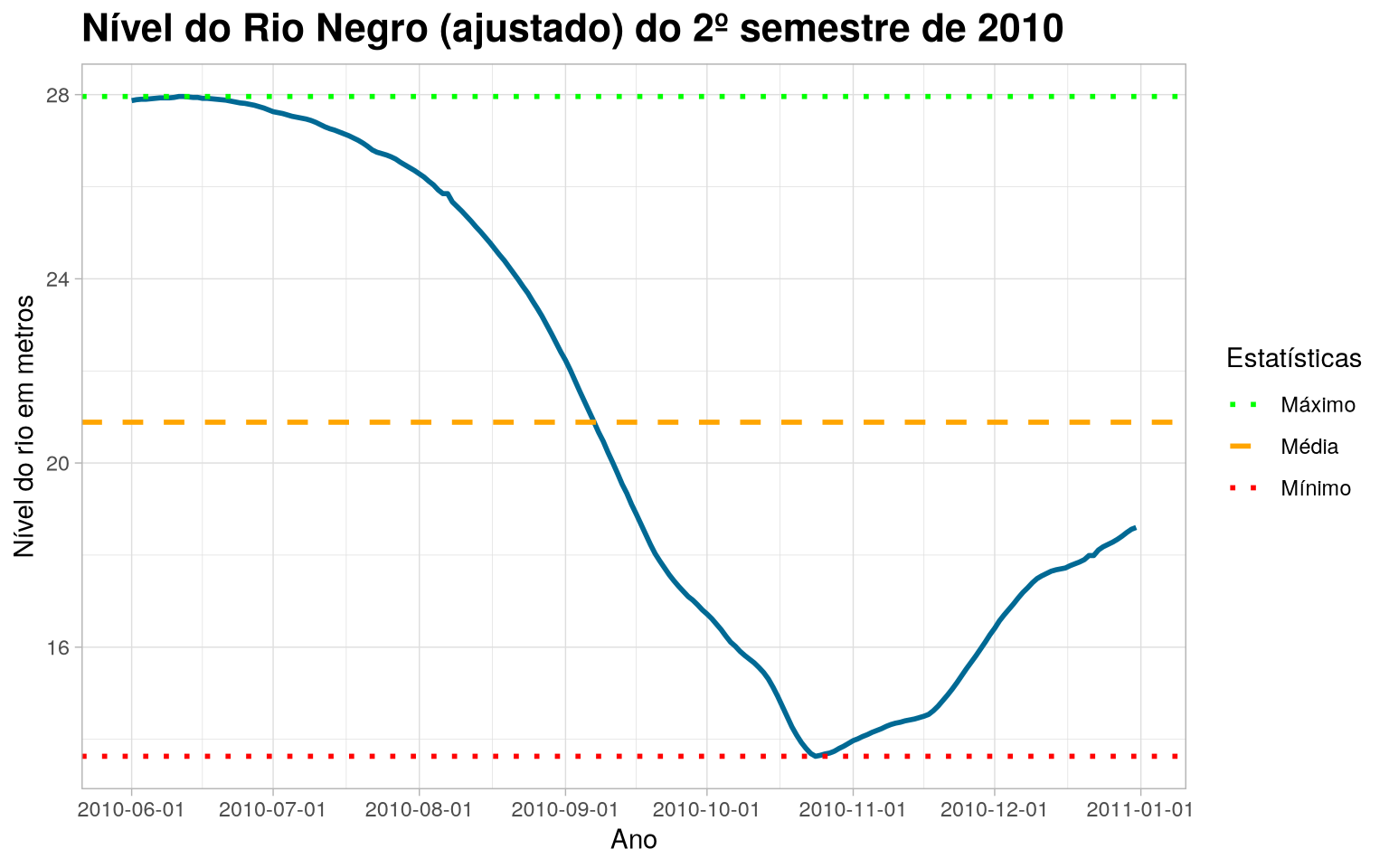
Portanto, é notável que o tratamento desses valores outliers, que foram considerados faltantes fez toda diferença na conclusão sobre os dados do nível do Rio Negro.